
サブグループ解析ってよく目にするけど、よく意義や注意点をわかっていなかった。今日勉強したことのまとめ。
①サブグループ解析はなんのためにするのか?
…効果の修飾があるかどうかを確認するため。
「効果の異質性」といって、例えばある集団全体を対象とした研究で「A薬投与が血圧低下に寄与する」という結果が得られたとしても、実は、その集団の中である遺伝子を持つ人たちだけにその事象が多くみられていて、ある遺伝子を持たない人では同じような効果が得られていないかもしれない、という現象がありうる。
効果の異質性を引き起こす原因となる因子(上記の例だと、ある遺伝子)を、効果の修飾因子という。
では、よく耳にする、「交絡因子」と、今回出てきた「効果を修飾する因子」とはどう違うのか?端的に図で表すと以下のようになる。
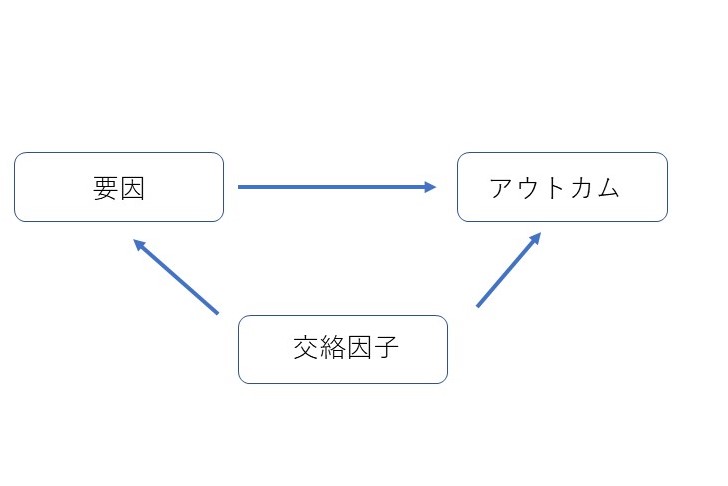
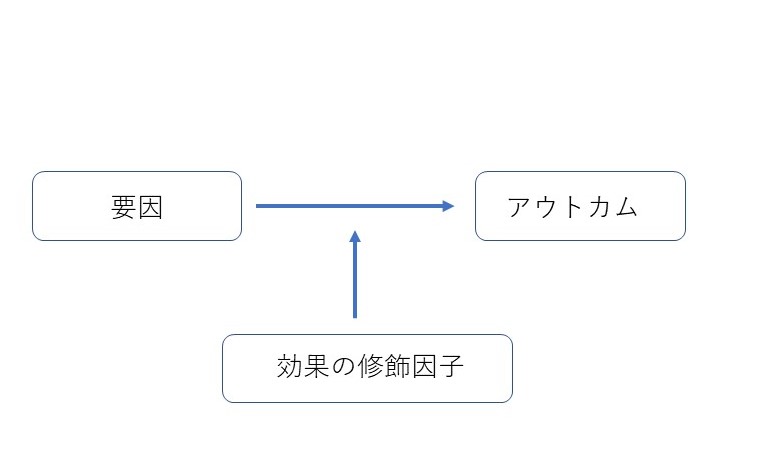
つまり、交絡因子は、要因とアウトカムの両方にそれぞれ影響を及ぼす因子であり、その存在によって、要因とアウトカムの関係性を真実よりも強くみせかけたり、弱くみせかけたりする。例えば…「コーヒーをたくさん飲む人(要因)に肺癌が多く発生した(アウトカム)」という結果があったとして、実は、コーヒーをたくさん飲む人はタバコもたくさん吸っていた、という、コーヒーとタバコの関係があったとする。また、タバコと肺癌の発生にも、よく知られているように、関連がある。すると、実際にはコーヒーそれ自体と肺癌発生それ自体には関連がないかもしれないのに、初めに挙げたような結果が出てしまう。これが交絡。
交絡と、効果の修飾因子の違いが分かったところで、今日の本題。効果の修飾があるかどうかを確認するにはどうすればよいのか?
⇒ここで有用なのが、サブグループ解析。複数のサブグループに分けて解析することで、研究対象の集団内で効果の異質性があるのかどうかを探索することができる。また、その裏返しであるが、サブグループに分けて解析して、違いがなければ、効果に一貫性があるということを確認することができる。
②サブグループ解析の注意点
あるサブグループでは有意な結果が出なかったとして、それを本当に関連がないと結論づけるのは尚早。本当に関連がない場合もあるし、実はサブグループごとに交絡因子の組み合わせが違うのかもしれない。また、サンプルサイズが違うのかもしれない。そして、単なる偶然かもしれない。
③効果の修飾の統計学的な検証
理論的には、以下に示す方法などで、効果の修飾の統計学的な検証を行うことが可能である。しかし実際には、たいていの場合、検出力不足となって、検証することが難しい。
方法としては、交互作用項を含めた回帰モデルを用いる。
例えば…良いオリジナルの例が思いつかないが…定期的な生活指導という介入をした集団のほうが、介入しなかった集団よりも血圧が下がったという主要結果が出たとする。副次解析として、大酒家の人でも大酒家でない人でも、同じ結果が得られることを確認したい。
血圧低下=β1×生活指導+β2×飲酒量+β3×(生活指導×飲酒量)
というようなモデルにあてはめて検証する。うーん、この例でよいんだろうか。
